
Because I/O operations are usually slow and have side effect.
Because leveraging file system when crafting modern ecosystem is likely to end up killing performances and/or introducing API bias.
Because we deserve blazing fast performances without sacrificing agnosticity.
Because we can achieve it as first-step without having to stage our journey with this quick step which we do swear will for sure not stay but you know… we are used to.
Because - more than once - it is even cheaper to do things right from beginning despite our mistaken belief.
But mainly because it is fun, let’s dive in shared-memory-based data exchange.
Context
See how one could materialize our use case.

I advocated more than once to plug Observability early in project lifecycle. To be honest, it should compete with some other first-class citizen such as
CI/CDyou should consider setting up prior to write any line of code. I recently discovered.NET Aspire, and it seems to be a very good fit here. Mainly because it will allow us to move back and forth between bare-metal and containerized development while seamlessly performing the heavy lifting for us (service discovery, compose generation,OTELdash-boarding). Thus, ensuring wa can focus on spiking instead of dealing with necessary plumbing.
Data paradigm at its core is quite simple and can be sum up by introducing two actors, namely the data producer and the data consumer.

Here, we assume that consumer asks producer for data generation, is fed back by matching data ID and eventually fetches data from shared-memory leveraging this data ID. Obviously, producer has fed shared-memory with data upstream, prior to notify consumer with the said data ID. So, kind of dual-channel polling use case. Of course, we can easily revamp this to show case other patterns instead, such as the observer one.
It is quite common to end up with different specialized channels when two actors have to communicate. Here, a gRPC-based lightweight one to handle chat and a SHM-based bare-metal one to deal with data. Remember, how we are used to tackle attached document to email, either by embedding them or only providing link reader can used downstream. By uncoupling data from messaging, it is far easier to effectively deal with inherent and annoying data exchange yards, such as optimizing bandwidth, usage, storage, … But remember as well that at the end of the day it is all about tradeoff. Smart designs are the ones which take into account use case.
Result
I am used to leverage Unit Testing to show case usage instead of plain old main unfolding. Here, I decided to leverage Aspire dashboard to assess flow and surface compelling usage metrics. Most of you should be comfortable now with traces view which allow to grasp related call sequence easily:
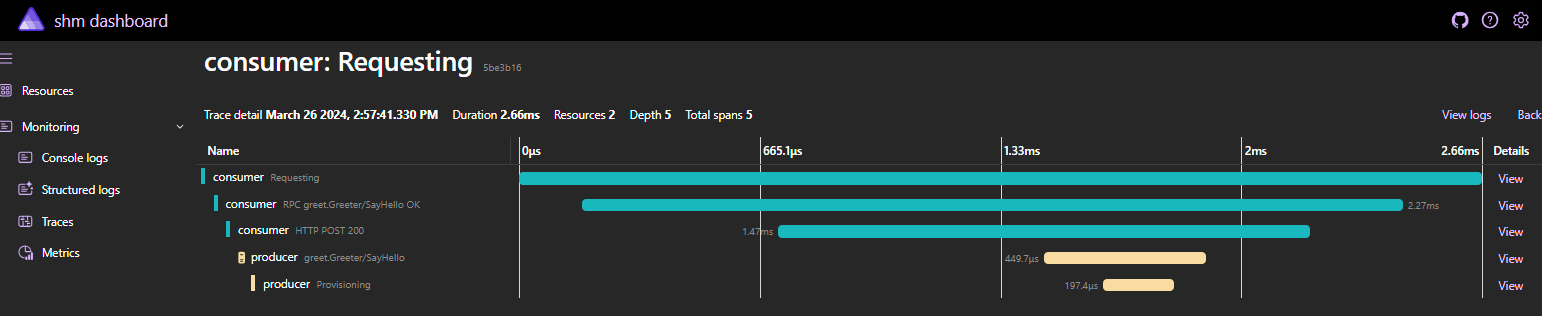
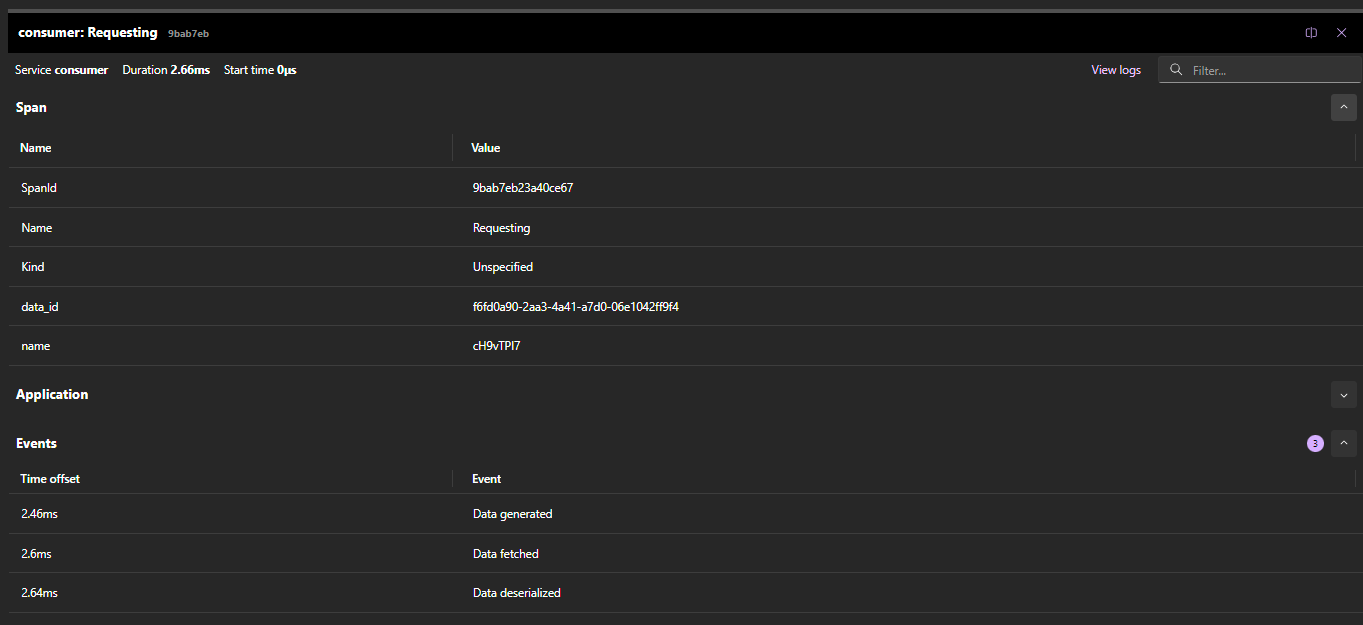
I took the opportunity to enrich basic OTEL instrumentation with tags and events to refine surfaced insights. It is a great addition to traces when you want to consolidate your telemetry.
Stack
Let’s look at the three different pieces we have in our system, namely producer, consumer and orchestration.
Producer
Slightly customizing a bare-metal dotnet new grpc template is enough to materialize our use case. Starting from the SayHello skeleton which has been generated for us from the protobuf contract, we can delegate data writing to a dedicated service while enriching telemetry instrumentation, ending up with the following:
|
|
Writing data to shared-memory is not OS agnostic, so we have to manually handle the switch. This said, whatever the language we are working with, there are already a lot of libraries to ease shared-memory interaction. Basically, we create a unique identifier for our data, serialize them and write them into shared-memory. Unique identifier is fed back to caller for downstream interaction. Pattern is well-known and not tight to shared-memory usage. Commonly used in real life as well, think about the way you drop your coat when arriving nightclub and claim it back later using the provisioned token.
|
|
Last but not least, a couple of lines to amend entry point with to unleash Aspire stack.
|
|
Consumer
Once again slightly customizing a bare-metal dotnet new worker template is enough to materialize our use case.
|
|
Reading from shared-memory is straightforward apart from the OS switch.
|
|
Once again, a couple of lines to amend entry point with to unleash Aspire stack. You may also notice how straightforward it is to register producer dependency. Service discovery feature will perform all the heavy lifting for us, ensuring dependency will be properly resolved at runtime whatever the deployment case we will be in.
|
|
Aspire
Aspire declarative setup is crystal clear.
|
|
Deployment
Aspire
A plain old dotnet run on the Aspire host project is all you need to get an up & running stack.

You can explore telemetry through Aspire dashboard.
Docker compose
Leveraging Aspirate, we can draft our deployment stack. Obviously, Aspire is not aware of the fact we leverage shared-memory for data exchange so we need to tweak a bit the deployment. To do so, a good habit is to introduce a siblings compose.override.yaml file to gather runtime configuration, such as:
|
|
Important part is how ipc feature is set up, allowing both consumer and producer to share the same memory space:
|
|
Once done you can mount the whole stack, complementing Aspirate auto-generated compose.yml file:
|
|

and eventually browse Aspire dashboard to explore telemetry.
Closing
We saw today how easy it is to setup our stack and show case shared-memory-based data exchange. In fact, most of the code we need has been added to this post and I spent more time breaking thing down than developing them. You may notice that I decided to pick grpc and worker templates for my actors, ending up with this protobuf contract to rule our messaging channel. As stressed before and because we opted for a dual-channel design, nothing prevent us to switch gRPC with REST for messaging. One interesting thing with gRPC lies in its amazing ecosystem which is by design language agnostic, meaning it lets door more than open to team up heterogenous producers and consumers. Same goes for shared-memory, nothing prevents us to write from one language and read from another one, apart to share serialization schema, which is also provided for free by the protobuf toolchain. You may also notice that we opted for an immutable data design which enables also some interesting capabilities downstream and get rid of the lock mechanism you are likely ending up with if you have decided to dump data into files, as you have to deal with both reader and writer timeline and cardinality… You may also potentially notice that the GimmeDataQuery method signature is a bit weird. My bad for this one, I forgot to mention this code has been auto-generated from the protobuf contract by plugging into the gRPC toolchain..
Closing one topic and surfacing a bunch of new ones, isn’t it what we call a good spike session..
Annex
Aspire auto-generated compose
|
|
Protobuf contract
gRPC contract is written via protobuf format, declaring both language agnostic data structures and operations while benefiting from auto-generated plumbing code (base class, helpers, …).
|
|